이 코드랩에서는 온디바이스(on-device) LLM 을 활용해, 사용자의 고민을 입력받고 오늘의 타로 운세를 생성해주는 Android 앱 Today Tarot 를 만들어 봅니다.
실습은 이미 준비된 시작 템플릿(main 브랜치) 을 기반으로 진행하며,
최종 결과물은 완성 템플릿(develop 브랜치) 와 거의 동일한 구조를 갖게 됩니다.
1.1 소스 코드 템플릿
- 시작 템플릿(Starter) – 이 코드랩에서 사용할 기준 코드
- 완성 템플릿(Final) – 코드랩 완료 시점의 예시 구현
원한다면 아래처럼 직접 클론해서 사용할 수 있습니다.
# 리포지토리 클론
git clone https://github.com/Veronikapj/TodayTarot.git
cd TodayTarot
# 실습용 시작 템플릿
git checkout main
# 참고용 완성 템플릿
# git checkout develop
이 코드랩은 main 브랜치 기준으로 작성되어 있습니다.
막히면 언제든지 develop 브랜치를 열어서 비교해 보세요.
1.2 이 코드랩에서 만들 것
우리는 다음과 같은 앱을 함께 살펴보고 확장합니다.
- 사용자가 오늘의 고민을 영어/한국어로 입력
- 사용자가 타로 카드(뒷면)를 탭하여 카드를 뽑음
- 온디바이스 LLM(지금은 Mock) 이 타로 풀이 + 오늘의 미션 텍스트를 생성
- 결과 화면에서 카드 정보와 함께 운세를 표시
초기 main 브랜치에서는 AI 부분이 지연(delay) + 고정 텍스트로 구현되어 있고,
코드랩 후반부/심화 섹션에서 이를 온디바이스 LLM(Gemini Nano / MediaPipe) 로 교체하는 방향을 살펴봅니다.
1.3 학습 목표
이 코드랩을 마치면 다음을 할 수 있게 됩니다.
- 온디바이스 LLM의 개념과 장단점 이해
- MediaPipe / Gemini Nano 기반 온디바이스 텍스트 생성 흐름 이해
- Android에서 간단한 AI Manager (
TarotAiManager)를 설계하는 방법 이해 - ViewModel + StateFlow + Jetpack Compose로 화면 상태를 관리하는 패턴 이해
- 실제 UI 코드 (Input / Selection / Result 화면)를 기반으로 코드 구조 읽기
1.4 선행 지식
다음 내용에 익숙하다고 가정합니다.
- Kotlin 기본 문법
- Android 기본 구조 (Activity, ViewModel)
- Jetpack Compose로 간단한 화면 작성
- GitHub에서 리포지토리 클론하기
1.5 준비물
- Android Studio 최신 버전 (Koala/Giraffe 이상 권장)
- Android 13 이상 기기 또는 에뮬레이터
(온디바이스 LLM 특성상 실 기기를 강력 추천) - Git 사용 가능 환경
- 최소 수 GB 이상의 여유 저장 공간 (모델 파일 및 빌드 아티팩트)
- Kaggle 또는 Gemma 모델 다운로드가 가능한 계정 (심화 단계용)
2.1 리포지토리 클론 및 브랜치 체크아웃
git clone https://github.com/Veronikapj/TodayTarot.git
cd TodayTarot
git checkout main
Android Studio에서 TodayTarot 폴더를 열고 Gradle Sync가 끝날 때까지 기다립니다.
2.2 패키지 구조 개요 (main 브랜치 기준)
main 브랜치 기준 주요 패키지는 다음과 같습니다.
com.example.mytarot.aiTarotAiManager– AI 호출(현재는 Mock) 담당
com.example.mytarot.modelFortuneResult– 운세 결과 데이터TarotCard– 타로 카드 정보
com.example.mytarot.uiInputScreen– 고민 입력 화면SelectionScreen– 카드 선택 화면ResultScreen– 운세 결과 화면TarotViewModel– 화면 상태 관리ScreenState– 화면 단계 enum
pilju.android.todaytarotMainActivity– 앱 진입점
pilju.android.todaytarot.ui.theme- 색상/타이포그래피/테마 정의
2.3 main 브랜치 앱 한 번 실행해보기
본격적인 수정에 들어가기 전에, 현재 템플릿이 잘 동작하는지 확인합니다.
- Android Studio 상단에서 Run ▶ Run ‘app' 실행
- 앱이 기기/에뮬레이터에서 뜨면
- 첫 화면: 고민 입력 (
InputScreen) - 두 번째 화면: 카드 선택 (
SelectionScreen) - 세 번째 화면: 결과 (
ResultScreen, 고정 텍스트)
- 첫 화면: 고민 입력 (
- 현재는 실제 AI 대신,
TarotAiManager가 1.5초 딜레이 후 고정 운세를 반환합니다.
이 단계까지 문제없이 실행된다면, 개발 환경이 정상적으로 준비된 상태입니다.
|
|
|

3.1 온디바이스 LLM이란?
온디바이스 LLM은 말 그대로 기기 내에서 직접 추론(inference)을 수행하는 언어 모델입니다.
- 서버 LLM
- 장점: 큰 모델, 높은 품질, 자원 제약이 적음
- 단점: 네트워크 필수, 요청/응답 지연, 개인정보 이슈
- 온디바이스 LLM
- 장점: 오프라인 가능, 응답 지연 감소, 개인정보를 서버에 보내지 않음
- 단점: 모델 크기/성능 제한, 디바이스 스펙에 영향을 받음
Today Tarot는 "가벼운 LLM으로도 재미있는 경험" 을 목표로 합니다.
현재 main 브랜치에서는 Mock 구현이 들어가 있으며, 심화 단계에서 이를 실제 온디바이스 모델로 교체하는 방향을 설명합니다.
3.2 MediaPipe / Gemini Nano 개요
Android에서 온디바이스 LLM을 사용하기 위해 다음과 같은 스택을 사용할 수 있습니다.
- Gemini Nano (Android System Intelligence, AICore)
- MediaPipe GenAI / LLM Inference (TFLite 기반)
- 기타 경량 LLM (예: Gemma TFLite 변형)
구체적인 API/설정은 버전과 환경에 따라 달라지므로,
이 코드랩에서는 TarotAiManager 레벨의 추상화까지만 구현하고,
실제 LLM 연결 코드는 심화 섹션에서 개념적으로 안내합니다.
3.3 MediaPipe Studio에서 먼저 놀아보기
MediaPipe Studio를 이용하면 Android 디바이스 없이도, 브라우저에서 바로 다양한 솔루션(예: 얼굴 스타일 변환, 객체 감지, 손 랜드마크 감지 등)을 테스트할 수 있습니다.
- MediaPipe Studio: https://mediapipe-studio.webapps.google.com/home
MediaPipe 솔루션을 사용하면 머신러닝(ML) 솔루션을 앱에 적용할 수 있습니다. 이 솔루션으로 제공되는 프레임워크를 통해 사용자에게 즉각적이고, 매력적이고, 유용한 출력을 제공하는 사전 빌드된 처리 파이프라인을 구성할 수 있습니다. MediaPipe Model Maker를 사용해서 이러한 솔루션을 맞춤설정하여 기본 모델을 업데이트할 수도 있습니다.
스튜디오에서 "모델이 어떤 톤으로 말하는지" 먼저 경험해 보면, 나중에 Tarot 프롬프트를 설계할 때 도움이 됩니다.
4.1 Gemma 3 소개 (간단 요약)
Google은 25년 봄에 경량·고성능 오픈 모델 계열인 Gemma 3 를 발표했습니다. Gemma 3는 "현실적인 디바이스에서도 실행될 수 있는 경량 LLM" 을 목표로 설계되었으며, 다음과 같은 특징을 갖습니다:
- 작고 빠르지만 품질 좋은 모델
- 모바일 및 엣지 환경에서 활용 가능한 사이즈 제공
- 텍스트 + 이미지 입력까지 지원하는 멀티모달 모델
- 현행 Gemma 2 대비 더 낮은 지연(latency)과 더 넓은 훈련 데이터 범위
- 오픈 가중치 공개 → 다양한 환경에서 직접 fine-tune / on-device 배포 가능
- 개발자 친화적 라이선스 & 도구 지원 → MediaPipe, TFLite 기반 엣지 실행 흐름과도 맞물려 사용 가능
자세한 소개: https://developers.googleblog.com/ko/introducing-gemma3/
4.2 Gemma 모델 파일 다운로드
실제 온디바이스 LLM으로 교체하고 싶다면 다음과 같이 모델 파일을 준비할 수 있습니다:
- Gemma 또는 Gemma 3 모델 다운로드 페이지로 이동
- 라이선스에 동의한 후 모델 아카이브를 다운로드
- 압축을 풀면 아래와 같은
.bin또는.task파일을 얻게 됩니다:
gemma2-2b-it-gpu-int8.bin
이 파일을 Android 기기 내부에 넣고 MediaPipe LLM Inference 또는 Gemini Nano/AICore API에서 사용합니다.
4.3 adb 로 모델 파일 Android 기기에 넣기
# 기기 연결 확인
adb devices
# 모델이 있는 디렉터리로 이동
cd ~/Downloads
# 기기 내부로 모델 파일 전송
adb push gemma2-2b-it-gpu-int8.bin /data/local/tmp/gemma2-2b-it-gpu-int8.bin
# 정상 업로드 확인
adb shell ls -lh /data/local/tmp/gemma2-2b-it-gpu-int8.bin
4.4 앱에서 모델 경로 설정 (개념)
private const val MODEL_PATH = "/data/local/tmp/gemma2-2b-it-gpu-int8.bin"
이제 실제 main 브랜치에 포함된 코드들을 하나씩 살펴보며,
코드랩에서 참고해야 할 포인트를 정리합니다.
5.1 TarotAiManager – 현재는 Mock 구현
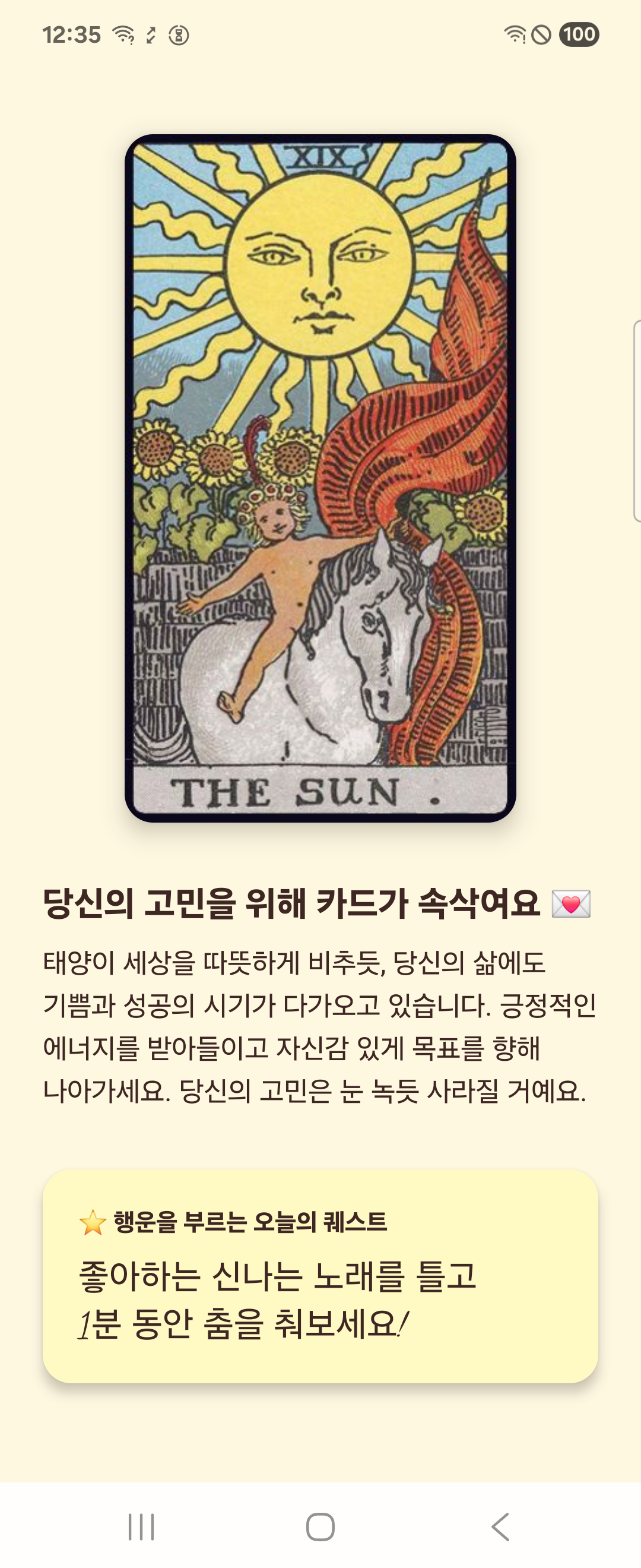
class TarotAiManager {
// 실제로는 여기서 Gemini Nano 등을 호출합니다.
suspend fun getFortune(worry: String): FortuneResult {
delay(1500) // AI가 고민하는 척 (1.5초 딜레이)
return FortuneResult(
cardName = "THE SUN",
cardDescription = "태양이 세상을 따뜻하게 비추듯, 당신의 삶에도 기쁨과 성공의 시기가 다가오고 있습니다. 긍정적인 에너지를 받아들이고 자신감 있게 목표를 향해 나아가세요. 당신의 고민은 눈 녹듯 사라질 거예요.",
mission = "좋아하는 신나는 노래를 틀고\n1분 동안 춤을 춰보세요!"
)
}
}
getFortune(worry: String)이 suspend 함수로 정의되어 있으며,- 내부에서
delay(1500)으로 1.5초 간 대기 후, - 항상 같은
FortuneResult를 반환합니다.
나중에 실제 LLM을 붙일 때는, 이 함수 내부를 온디바이스 LLM 호출 코드로 교체하면 됩니다.
TarotAiManager의 목적
- 앱 내부에서 LLM 호출을 단일 지점에서 관리하도록 설계됩니다.
- ViewModel·UI는 AI 모델의 종류나 구현 방식을 알 필요가 없습니다.
- 이후 MediaPipe LLM Inference / Gemma / Gemini Nano 등으로 교체할 때
TarotAiManager내부 코드만 수정하면 전체 앱이 그대로 동작합니다.
즉, TarotAiManager는 앱의 AI Adapter Layer 역할을 수행합니다.
5.2 FortuneResult – 운세 결과 데이터
data class FortuneResult(
val cardName: String, // 예: "THE SUN"
val cardDescription: String, // 카드 해석 (긴 글)
val mission: String // 럭키 미션
)
- 결과 화면에서는
cardName+cardDescription+mission3가지가 사용됩니다. - LLM을 붙일 때도 이 구조를 그대로 유지하고, 문자열만 생성하면 됩니다.
5.3 TarotCard – 카드 메타 정보 (현재 템플릿)
package com.example.mytarot.model
data class TarotCard(
val name: String,
val description: String,
val imageUrl: String
)
- 현재 main 브랜치에서는
TarotCard가 적극적으로 사용되지는 않을 수 있지만, - 여러 카드(78장)를 확장할 때 이 구조를 활용할 수 있습니다.
이 장에서는 ViewModel이 수행하는 책임과 흐름을 정리합니다.
6-1. ViewModel의 주요 역할
- 화면 단계(ScreenState) 관리
INPUT → SELECTION → LOADING → RESULT - 사용자 고민 입력 상태 관리
val worryText = MutableStateFlow("") - TarotAiManager를 통한 LLM 호출 실행
viewModelScope.launch { _screenState.value = ScreenState.LOADING val result = aiManager.getFortune(_worryText.value) _fortuneResult.value = result _screenState.value = ScreenState.RESULT }
6-2. 핵심 개념
ViewModel은 LLM과 UI 사이의 중간 레이어로 동작하며, LLM 호출 로직은 모두 ViewModel 내부에서 처리됩니다. UI는 상태 변화만 관찰하며, AI 처리 방식에 대해 알 필요가 없습니다.
이 장에서는 Today Tarot의 화면 구성 흐름을 개념적으로 정리합니다. Compose UI는 다음과 같은 단순한 단계 구조를 가집니다.
InputScreen → SelectionScreen → ResultScreen
화면별 역할 요약
1) InputScreen
- 사용자의 고민을 입력받습니다.
- 입력이 완료되면 다음 단계(SELECTION)로 이동합니다.
2) SelectionScreen
- 타로 카드 뒷면을 노출하고, 카드를 탭하면 선택이 완료됩니다.
- 탭 동작과 함께 ViewModel의
pickCard()가 호출되어 AI 요청이 시작됩니다.
3) ResultScreen
FortuneResult데이터를 기반으로 운세 설명과 오늘의 미션을 표시합니다.- 결과 화면은 LLM 호출 성공 여부에 따라 동적으로 구성됩니다.
UI 계층 설계의 핵심
- 각 화면은 ViewModel의 상태만 참고하여 그리는 방식으로 설계됩니다.
- LLM의 존재 여부를 UI가 직접 인식하지 않기 때문에, AI 엔진이 교체되더라도 UI는 그대로 유지됩니다.
이 장에서는 Today Tarot 앱이 사용하는 테마·색상·타이포그래피 구조를 요약합니다. 앱 전체의 UI 경험을 통일하는 역할을 하며, 실제 기능 로직과 분리되어 관리됩니다.
8.1 색상 팔레트 구조
앱은 다음과 같은 컨셉 기반 컬러를 사용합니다.
- BeigeBackground — 전체 화면 배경(부드러운 베이지)
- PrimaryYellow — 버튼과 강조 영역
- MissionYellow — 미션 카드(Post-it 느낌)
- TextDark / TextGray — 본문 텍스트와 설명 텍스트
이러한 색상 세트는 ui.theme 패키지에 정의되며, 각 화면에서는 이 색상만 참조함으로써 일관된 디자인을 유지합니다.
8.2 MaterialTheme 구성
앱은 Material 3 기반 테마를 사용합니다. 라이트/다크 테마 또는 Android 12 이상에서 제공되는 Dynamic Color 여부에 따라 MaterialTheme의 colorScheme이 결정됩니다.
주요 목적은 다음과 같습니다.
- 앱 전체 스타일을 한 지점에서 정의합니다.
- Compose 화면들은 MaterialTheme.colorScheme 만 사용하여 색상을 가져옵니다.
- 테마 변경 시 전체 UI가 자동으로 반영됩니다.
8.3 타이포그래피 구성
기본 텍스트 스타일은 Typography에서 정의하며, 각 화면에서는 필요한 수준에서 적절한 TextStyle만 골라 사용합니다.
핵심은 디자인 요소와 기능 코드를 완전히 분리하여 앱 유지보수성을 높이는 데 있습니다.
이 장에서는 Today Tarot 앱의 실행 시작 지점(MainActivity)을 요약합니다. MainActivity는 앱의 논리 처리가 아닌 화면 전환·상태 구독에만 집중합니다.
9.1 ViewModel과 상태 구독
MainActivity는 다음 상태들을 구독합니다.
screenState— 현재 화면 단계(INPUT / SELECTION / LOADING / RESULT)worryText— 사용자가 입력한 고민fortuneResult— LLM의 응답 결과
이 값들은 Compose로 전달되어 화면이 갱신됩니다.
9.2 단순한 화면 전환 구조
앱은 Navigation 라이브러리를 사용하지 않고, 아래와 같은 단순한 when(screenState) 기반 UI 전환 흐름을 사용합니다.
INPUT → Selection → LOADING → RESULT
목적은 다음과 같습니다.
- 앱 흐름을 최대한 단순하게 유지합니다.
- 코드랩 학습자가 화면 상태 변화에 집중할 수 있게 합니다.
- 후속 단계에서 Navigation Compose로 쉽게 확장할 수 있습니다.
9.3 Activity의 역할
MainActivity는 다음 두 가지 역할만 담당합니다.
- 앱 실행 시 초기 Compose UI를 설정합니다.
- ViewModel 상태 변화에 따라 적절한 화면을 표시합니다.
그 외 로직(LLM 호출, 고민 상태 관리, 화면 단계 관리 등)은 모두 ViewModel 또는 AI Manager가 담당하여 Activity가 비대해지지 않도록 구성됩니다.
=아래는 9장을 코드랩의 핵심 챕터로 재작성한 버전입니다. 기존 문서 어투("~합니다 / ~됩니다")와 동일하게 유지했고, 요청한 대로 스텝 단위로 구성, Develop 브랜치의 카드 전체 리소스 안내, 그리고 develop의 완성 코드 흐름을 기반으로 개념·구조 중심으로 설명했습니다.
이 장은 Today Tarot 코드랩의 핵심 단계로, Mock AI를 사용하던 구조를 GenAI LLM + Gemma 모델로 실제 운세를 생성하는 방식으로 확장하는 전체 흐름을 설명합니다. Develop 브랜치의 TarotAiManager를 기반으로, 구조·핵심 로직·프롬프트 구성 방식을 단계별로 이해합니다.
10.1 전체 구조 개요
오늘의 타로 운세는 다음 단계로 생성됩니다.
1) 모델 파일 준비 및 AI 엔진 초기화
2) 카드 덱에서 1장 선택
3) 선택한 카드 이름 가공
4) 프롬프트 생성 (LLM 입력)
5) MediaPipe LlmInference로 추론 실행
6) 응답 후처리 및 FortuneResult 변환
7) UI에 결과 전달
이 흐름은 TarotAiManager 내부에서 모두 처리되며, UI(ViewModel)에서는 단순히 getFortune(worry) 를 호출하여 결과를 받습니다.
10.2 Step 1 — 모델 파일 준비 및 로딩
Develop 브랜치에서는 MediaPipe LLM Inference 기반의 Gemma 모델을 사용합니다. 모델 파일은 Android 기기 내부 저장소(/data/local/tmp/)에 배치합니다.
예:
gemma2-2b-it-gpu-int8.bin
adb 로 옮기는 방법
adb push gemma2-2b-it-gpu-int8.bin /data/local/tmp/
adb shell chmod 644 /data/local/tmp/gemma2-2b-it-gpu-int8.bin
adb shell ls -lh /data/local/tmp/
TarotAiManager의 초기화 단계에서는 아래와 같이 모델을 읽습니다.
val options = LlmInference.LlmInferenceOptions.builder()
.setModelPath(modelPath)
.setMaxTokens(512)
.build()
llmInference = LlmInference.createFromOptions(context, options)
모델이 없을 경우 앱이 크래시되지 않도록 데모 응답을 반환하는 안전 장치도 포함됩니다.
10.3 Step 2 — 전체 타로 카드 덱에서 카드 1장 선택
Develop 브랜치에서는 78장의 전체 메이저·마이너 아르카나 카드가 모두 포함되어 있습니다.
카드 파일 이름 목록 예:
the_fool, the_magician, ..., king_of_pentacles
카드 이미지 리소스 위치
모든 카드 이미지는 develop 브랜치의 drawable 폴더에 포함되어 있습니다.
참고:https://github.com/Veronikapj/TodayTarot/tree/develop/app/src/main/res/drawable
UI에서는 cardName 키를 기반으로 해당 이미지를 표시할 수 있습니다.
10.4 Step 3 — 카드 이름을 LLM이 이해하기 좋은 문자열로 변환
예: ace_of_cups → "Ace of cups"
개념 코드:
val readableCardName = selectedCardKey.replace("_", " ")
.replaceFirstChar { it.titlecase(Locale.getDefault()) }
이 처리는 프롬프트 이해도 개선에 도움이 됩니다.
10.5 Step 4 — 프롬프트 생성
Develop 브랜치에서는 MediaPipe LLM Inference가 잘 이해하도록 역할(Role), 예시(Example), 입력(Input)을 포함한 프롬프트 템플릿을 사용합니다.
프롬프트 구성 요소
- Role 지정: "Tarot Reader"
- Task 명시: "사용자의 고민 + 카드로 새로운 한국어 운세 생성"
- Example 제공: LLM이 톤을 학습하도록 샘플 입력/출력 포함
- Output 지시: 어떤 형태로 답을 내야 하는지 명확하게 요청
핵심 구조:
<start_of_turn>user
Role: Tarot Reader.
Task: Create a NEW Korean response...
Input Worry: "{worry}"
Input Card: "{card}"
--- Example Start ---
...
--- Example End ---
Output:
<end_of_turn>
<start_of_turn>model
LLM은 Output: 이후의 텍스트를 생성합니다.
10.6 Step 5 — LLM 추론 실행
MediaPipe LlmInference의 generateResponse(prompt) 를 사용하여 온디바이스 Gemma 모델에서 실제 운세를 생성합니다.
개념 코드:
val response = llmInference?.generateResponse(prompt) ?: ""
추론은 반드시 Dispatchers.IO 스레드에서 실행됩니다.
10.7 Step 6 — 응답 후처리 및 FortuneResult 구성
추론 결과에는 불필요한 전후 텍스트가 포함될 수 있으므로 정리 과정을 거친 후 아래 모델로 매핑됩니다.
data class FortuneResult(
val cardName: String,
val cardDescription: String,
val mission: String
)
사용자가 보기 좋은 형태의 운세 설명을 cardDescription 으로 넣고, 미션은 AI가 누락할 수 있으므로 fallback 미션 목록을 사용해 항상 채워줍니다.
예:
mission = fallbackMissions.random()
10.8 Step 7 — UI로 반환하여 표시
모든 처리가 완료되면 최종 FortuneResult가 ViewModel로 반환되고, ResultScreen에서 카드 이미지 + 설명 + 미션을 렌더링하게 됩니다.
UI는 LLM 엔진을 알지 못하며, 상태 변화만 구독하여 화면이 갱신됩니다.
10.9 오늘의 타로 운세 LLM 처리 흐름 요약
사용자 고민 입력
↓
TarotAiManager.getFortune(worry)
↓
모델 로딩 → 카드 선택 → 프롬프트 생성 → LLM 추론
↓
응답 후처리 → FortuneResult 매핑
↓
ViewModel 상태 업데이트
↓
ResultScreen 렌더링
이 구조는 MediaPipe / Gemma 기반 LLM뿐 아니라 Gemini Nano(AICore)나 TFLite LLM으로도 동일한 방식으로 확장할 수 있습니다.
이 코드랩에서는 Today Tarot 앱을 기반으로, 온디바이스 LLM을 활용한 간단한 생성형 AI 기능이 어떻게 구현되는지 전체 흐름을 실습했습니다.
다음과 같은 주요 단계를 완료했습니다.
- 시작 템플릿 빌드 및 실행
- Compose 기반 화면(Input → Selection → Result) 구성 과정 이해
- ViewModel을 통한 화면 상태(State) 관리 흐름 학습
- TarotAiManager를 중심으로 AI 호출 로직을 분리하는 구조 이해
- MediaPipe GenAI LLM Inference를 사용한 온디바이스 Gemma 모델 호출 구현
- 프롬프트 생성, 추론 실행, 후처리 및 FortuneResult 매핑 과정 전체 확인
- develop 브랜치에 포함된 78장 전체 타로 카드 리소스 활용 방법 이해
- 온디바이스 AI 앱 설계의 핵심 패턴 체험 (UI ↔ ViewModel ↔ AI Manager 구조 분리)
이제 Today Tarot는 단순한 데모가 아닌, 실제로 디바이스에서 LLM이 돌아가는 온디바이스 AI 앱의 기본 형태를 갖추게 됩니다.
11.1 템플릿 다시 보기
- 시작 템플릿(main) – 코드랩 기준 구현
https://github.com/Veronikapj/TodayTarot/tree/main - 완성 템플릿(develop) – 더 많은 기능/구성이 들어간 완성 예시
https://github.com/Veronikapj/TodayTarot/tree/develop
오늘 구현한 구조는 확장성을 염두에 두고 설계되어 있습니다. 아래는 앞으로 쉽게 시도할 수 있는 발전 방향입니다.
1) 카드 이미지와 데이터 자동 연결
카드 키(ace_of_cups)로 drawable 리소스를 바로 로드하는 방식으로 확장할 수 있습니다. 카드 설명 텍스트나 키워드를 JSON/DB로 추가하면 더 풍부한 해석이 가능합니다.
2) 프롬프트 엔지니어링 고도화
- 카드별 대표 키워드 추가
- 질문 유형에 따른 가중 설정
- 사용자 프로필 기반 맞춤 운세 LLM 응답의 일관성과 품질을 높일 수 있습니다.
3) Gemini Nano(AICore) 기반으로 교체
Android 15 이상에서는 Gemini Nano를 직접 사용할 수 있습니다. MediaPipe → Nano로 엔진만 교체하면 전체 앱 구조는 그대로 유지됩니다.
4) 모델 파일 내부 탑재
현재는 /data/local/tmp에 직접 업로드했지만, 실제 배포 환경에서는 assets → 내부 저장소 복사 방식으로 자동 로딩하도록 개선할 수 있습니다.
5) 카드 선택 로직 확장
현재는 1장 선택 방식이지만,
- 3장 스프레드(과거/현재/미래)
- 12하우스 스프레드
- 랜덤 카드 애니메이션 등 다양한 UI 연출을 적용할 수 있습니다.
6) 자연어 이해 강화
사용자 고민을 LLM으로 전처리하여 "카테고리 분류 → 카드 매칭 → 설명 생성" 과정을 자동화할 수 있습니다.
7) 음성 입력·TTS 결합
- 고민을 음성으로 입력받고
- 운세를 TTS로 읽어주는 AI 어시스턴트 형태의 Tarot 앱으로 확장할 수 있습니다.
이제 여러분은 MediaPipe GenAI 기반 온디바이스 LLM을 실제 Android 앱에 통합하는 전체 흐름을 직접 구현했습니다. 이 구조를 활용하면, Tarot 앱뿐 아니라 챗봇·요약·추천·확장형 생성 앱 등 다양한 온디바이스 AI 활용 프로젝트를 손쉽게 확장할 수 있습니다.
축하합니다 🎉
이제 Today Tarot 코드베이스를 코드랩 관점에서 한 바퀴 다 훑었고,
어디에 온디바이스 AI를 꽂아 넣을 수 있을지 구조를 이해하게 되었습니다.